
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 계산기
- 스케줄러
- 프로그래머스
- Effective Java
- spring boot
- 추상클래스
- 코드카타
- 디자인 패턴
- 이펙티브 자바
- lv1
- 스프링
- 템플릿 메서드 패턴
- 토스
- redis
- 자바
- GoF 23
- 프록시 패턴
- 로드밸런서
- Til
- 성능 개선
- Spring Batch
- Spring
- java
- 빌더 패턴
- 백엔드
- 김영한
- DB
- 스프링 배치
- 트러블슈팅
- 배치
- Today
- Total
김코딩
[Spring Batch] 3편. Chunk 기반 처리의 원리와 Job/Step 구조 본문
들어가며
1편에서는 Spring Batch가 왜 필요한지, 2편에서는 Job/JobInstance/JobExecution의 관계를 다뤘다. 여기까지는 "무엇을 위한 프레임워크인가"에 대한 이야기였다.
이번 편부터는 드디어 실제 구조와 코드를 본다. 이 글에서는 Spring Batch의 실행 단위인 Step이 어떻게 생겼는지, 그리고 Chunk 기반 처리가 내부에서 어떻게 돌아가는지 정리한다.
💭 나의 생각
개념을 탄탄히 다진 뒤에 코드를 보니 이해 속도가 확실히 달랐다. 웨이트리프팅을 할 때도 기본 자세가 잡혀있으면 새로운 종목을 배울 때 훨씬 빠르게 익혀지는 것과 같은 감각이다.
Job은 Step의 묶음이다
1편에서 Job이라는 단어를 여러 번 썼지만, 실제로 Job 안에는 하나 이상의 Step이 들어있다. Job 자체가 데이터를 처리하는 게 아니라, Step들이 순서대로 실행되면서 실제 작업을 수행한다.
일상 비유로 이해해보자.

"저녁 준비"라는 Job은 세 가지 Step으로 나뉜다. 장보기, 요리하기, 설거지. 만약 요리하기 단계에서 실수가 있었다면 장보기를 다시 할 필요는 없다. 이미 완료된 단계는 건너뛰고 실패한 단계부터 다시 하면 된다.
Spring Batch도 똑같다. 일일 정산 Job을 "거래 조회 → 정산 계산 → 결과 저장" 같은 Step으로 나눠두면, 정산 계산에서 실패했을 때 거래 조회를 다시 하지 않고 정산 계산부터 이어서 실행할 수 있다. 이 상태는 2편에서 다룬 BATCH_STEP_EXECUTION 테이블에 기록된다.
💭 나의 생각
처음 이 구조를 봤을 때는 "그냥 하나의 Step으로 다 하면 안 되나?"라고 생각했다. 하지만 운영 중 장애를 떠올려보면 답이 나온다. 1시간짜리 배치에서 거의 끝날 때쯤 실패했는데 처음부터 다시 돌려야 한다면? 실패 포인트가 명확하게 구분되어 있을수록 운영 비용이 줄어든다. Step 분리는 "언제든 장애가 날 수 있다"는 전제 위에서 설계된 것이다.
Step의 두 가지 종류
Step을 구현하는 방식에는 두 가지가 있다. 이 구분이 중요한 이유는, 실무에서 어떤 방식을 선택할지 고민하는 첫 번째 지점이기 때문이다.

Chunk 기반 Step
데이터를 일정 단위로 읽고, 가공하고, 저장하는 과정을 반복하는 방식이다. Spring Batch를 쓰는 이유 대부분이 여기에 해당한다.
Spring Batch uses a "chunk-oriented" processing style in its most common implementation.
— Spring Batch Reference: Chunk-oriented Processing
회원 100만 명의 등급을 재계산하거나, 거래 내역을 일괄 정산하거나, 로그 파일을 DB로 적재하는 등 대량 데이터를 반복 처리해야 할 때 사용한다.
Tasklet 기반 Step
데이터 반복 없이 한 번 실행하고 끝나는 단순 작업에 쓴다.
- 오래된 파일 삭제
- 배치 시작 전 디렉토리 초기화
- 외부 API 한 번만 호출
이런 단발성 작업을 억지로 Chunk 방식으로 만들면 오히려 코드가 어색해진다.
💭 나의 생각
실무에서 마주칠 일의 대부분은 Chunk 기반일 것이다. Tasklet은 "이런 것도 있구나" 정도로 알아두고, 실제로 뭔가 준비/정리 성격의 전후 작업을 할 때 떠올리는 정도면 충분하다고 느꼈다.
Chunk 기반 Step의 3요소
Chunk 기반 Step은 세 가지 구성 요소로 이루어진다. ItemReader, ItemProcessor, ItemWriter다.

각 요소의 역할은 다음과 같다.
ItemReader - 1건씩 읽는다
- 데이터 소스(DB, 파일, API 등)에서 데이터를 가져오는 책임
- 내부적으로는 페이징이나 커서로 조회하지만, 반환은 1건씩 한다
- 이 덕분에 100만 건을 한 번에 메모리에 올리지 않는다 (OOM 방지)
ItemProcessor - 1건씩 가공한다 (선택 사항)
- Reader가 준 데이터를 변환하거나 필터링한다
- 변환: 입력 타입과 다른 타입으로 바꿔서 반환 가능
- 필터:
null을 반환하면 해당 건은 Writer로 전달되지 않는다 - 필요 없으면 생략할 수 있다
ItemWriter - Chunk 단위로 저장한다
- Processor가 준 결과를 모아서 한 번에 저장한다
- Chunk size가 1,000이면 1,000건짜리
List를 받아서saveAll이나 bulk insert 수행 - 여기가 성능 최적화의 핵심 포인트다
💭 나의 생각
이 설계가 정말 영리하다고 느꼈다. 읽기는 1건씩(메모리 안정성), 쓰기는 모아서(성능). 혼자서는 절대 한 번에 이런 구조로 설계하지 못했을 것이다. 현업에서 대용량 배치를 짜본 사람들의 노하우가 프레임워크 레벨로 녹아있는 느낌이다.
Chunk 처리 사이클
이제 위 3요소가 어떻게 돌아가는지 전체 흐름을 보자.

Chunk size가 1,000이라면 한 사이클은 다음과 같이 돌아간다.
1. Read 단계 - Reader가 1건씩 1,000번 호출되어 1,000건을 모은다
2. Process 단계 - Processor가 1건씩 1,000번 호출되어 1,000건을 가공한다
3. Write 단계 - Writer가 1,000건짜리 List를 받아서 한 번에 저장한다
4. Commit - 트랜잭션을 커밋한다
이 네 단계가 하나의 Chunk를 이루고, 전체 데이터가 다 처리될 때까지 반복된다. 공식 문서의 의사 코드로 보면 이 흐름이 더 명확하다.
List items = new ArrayList();
for (int i = 0; i < commitInterval; i++) {
Object item = itemReader.read();
if (item != null) {
items.add(item);
}
}
List processedItems = new ArrayList();
for (Object item : items) {
Object processedItem = itemProcessor.process(item);
if (processedItem != null) {
processedItems.add(processedItem);
}
}
itemWriter.write(processedItems);위 코드 블록 전체가 하나의 트랜잭션 안에서 실행된다. 즉 Chunk size = 트랜잭션 단위라는 말이 여기서 확인된다. 1편에서 "Chunk는 메모리 단위이자 트랜잭션 단위"라고 했던 이야기가 바로 이 구조에서 나온 것이다.
전체 코드 구조 미리보기
여기까지 이해했으면, Spring Batch 코드가 대략 어떻게 생겼는지 그림으로 그릴 수 있다. 구체적인 코드는 잠시 뒤에 보고, 먼저 Bean들이 어떻게 연결되는지 구조부터 확인하자.
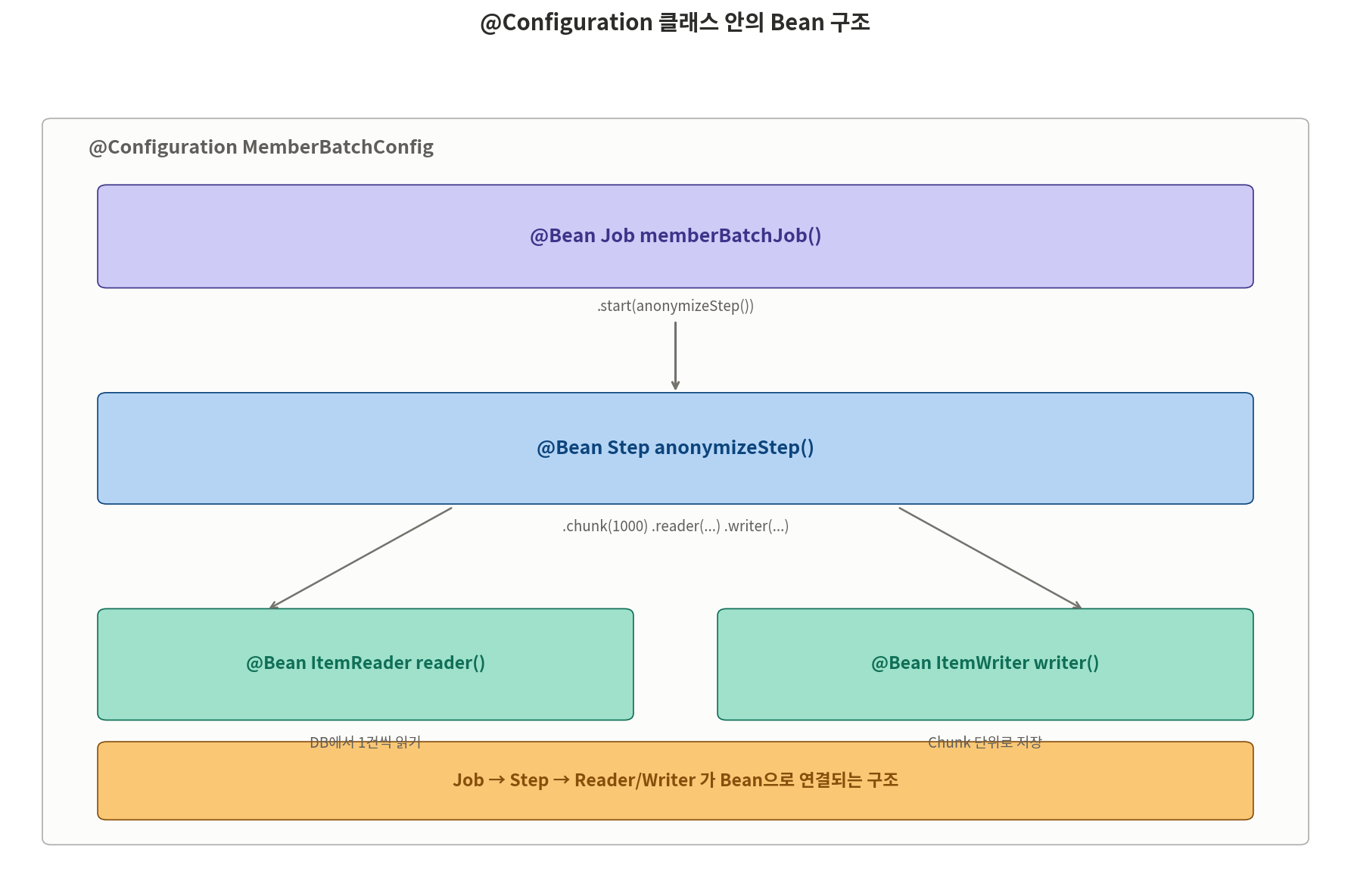
하나의 @Configuration 클래스 안에 네 개의 @Bean이 있다.
@Bean Job: 어떤 Step들을 순서대로 실행할지 정의@Bean Step: Chunk size와 Reader, Writer를 연결@Bean ItemReader: DB에서 1건씩 읽어오는 역할@Bean ItemWriter: Chunk 단위로 저장하는 역할
(간단한 예제라 Processor는 생략했다. 필요하면 @Bean ItemProcessor를 추가하면 된다.)
이 구조가 Spring Batch 코드의 90%이다. 어떤 배치든 이 뼈대에서 Reader/Processor/Writer 부분의 내용만 달라진다.
간단한 코드 예제
이제 실제 코드를 보자. 가능한 한 가장 단순한 예제로 시작한다.
시나리오
매일 새벽, 탈퇴한 회원의 이메일을 익명화한다. 탈퇴 시 개인정보를 즉시 삭제할 수 없는 법적 보관 기간이 있지만, 이메일은 바로 마스킹 처리해야 한다.
이 배치는 Processor가 필요 없다. DB에서 탈퇴 회원을 조회해서, 이메일을 deleted-{id}@masked.local 같은 형식으로 바꿔서 저장하면 끝이다. Reader와 Writer만으로 구현할 수 있다.
코드
@Configuration
@RequiredArgsConstructor
public class MemberAnonymizeBatchConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final MemberRepository memberRepository;
// ① Job 정의
@Bean
public Job memberAnonymizeJob() {
return new JobBuilder("memberAnonymizeJob", jobRepository)
.start(anonymizeStep())
.build();
}
// ② Step 정의 (Chunk 기반)
@Bean
public Step anonymizeStep() {
return new StepBuilder("anonymizeStep", jobRepository)
.<Member, Member>chunk(1000, transactionManager)
.reader(withdrawnMemberReader())
.writer(anonymizeWriter())
.build();
}
// ③ Reader - 탈퇴한 회원 조회
@Bean
public ItemReader<Member> withdrawnMemberReader() {
return new RepositoryItemReaderBuilder<Member>()
.name("withdrawnMemberReader")
.repository(memberRepository)
.methodName("findByStatus")
.arguments(List.of(MemberStatus.WITHDRAWN))
.pageSize(1000)
.sorts(Map.of("id", Sort.Direction.ASC))
.build();
}
// ④ Writer - 이메일 마스킹 후 저장
@Bean
public ItemWriter<Member> anonymizeWriter() {
return items -> {
items.forEach(member -> member.anonymizeEmail());
memberRepository.saveAll(items);
};
}
}코드 한 줄씩 해석
① Job 정의
new JobBuilder("memberAnonymizeJob", jobRepository)
.start(anonymizeStep())
.build();2편에서 다뤘듯이 "memberAnonymizeJob"이 Job 이름이고, 이 이름 + 파라미터 조합이 JobInstance의 유일성을 결정한다. .start()로 첫 Step을 연결하고, 여러 Step이 있다면 .next(step2()).next(step3()) 식으로 체이닝한다.
② Step 정의
.<Member, Member>chunk(1000, transactionManager)여기서 많은 게 설정된다.
<Member, Member>: Reader가 주는 타입 → Writer가 받는 타입. (Processor가 있으면 Processor 입출력 타입이 중간에 들어간다.)1000: Chunk size. 1,000건마다 커밋된다.transactionManager: Chunk 단위로 이 트랜잭션 매니저가 커밋을 담당한다.
③ Reader
RepositoryItemReaderBuilder
.methodName("findByStatus")
.arguments(List.of(MemberStatus.WITHDRAWN))
.pageSize(1000)RepositoryItemReader는 Spring Data JPA Repository를 Reader로 감싸주는 구현체다. 내부적으로 findByStatus(WITHDRAWN, PageRequest.of(0, 1000)) 같은 페이징 쿼리를 반복 호출해서 1,000건씩 조회한다.
pageSize와 chunkSize는 보통 같은 값으로 맞춘다. 다르게 해도 동작은 하지만, 쿼리 호출 횟수와 커밋 주기가 어긋나서 성능 측면에서 손해를 볼 수 있다.
Reader 종류(JpaPagingItemReader, JdbcCursorItemReader 등)별 차이점은 4편에서 다룬다.
④ Writer
items -> {
items.forEach(member -> member.anonymizeEmail());
memberRepository.saveAll(items);
};Writer는 ItemWriter<Member> 함수형 인터페이스를 람다로 구현한 것이다. 여기서 items는 Reader가 읽어온 1,000건짜리 List다. 각 회원의 이메일을 마스킹하고, saveAll로 일괄 저장한다.
실행 흐름 정리
위 배치가 실제로 돌아가는 흐름은 이렇다.
withdrawnMemberReader가 탈퇴 회원 1번을 읽는다- 1,000건이 모일 때까지 Reader를 반복 호출
anonymizeWriter가 1,000건짜리 List를 받아 이메일 마스킹 +saveAll- 트랜잭션 커밋
- 다음 1,000건(1,001~2,000) 처리 → 또 커밋
- 탈퇴 회원이 더 없을 때까지 반복
💭 나의 생각
실제 코드를 보니 개념 공부한 게 하나하나 연결되는 느낌이었다. "Chunk size가 1,000이면 1,000건마다 커밋된다"는 문장이 추상적이었는데, chunk(1000, transactionManager) 한 줄에 다 담겨있는 걸 보고 명확해졌다. 프레임워크가 좋은 추상화를 제공한다는 게 이런 뜻이구나 싶었다.
정리
이번 편에서 정리한 내용은 다음과 같다.
- Job은 Step의 묶음이고, Step 단위로 성공/실패가 기록된다
- Chunk 기반 Step은 Read → Process → Write → Commit 사이클을 반복한다
- Chunk size = 트랜잭션 단위다
- Reader는 1건씩 읽고, Writer는 모아서 저장해서 메모리 안정성과 성능을 동시에 잡는다
- Spring Batch 코드의 기본 구조는
@Configuration안의 Job/Step/Reader/Writer Bean 구성이다
다음 편에서는 이번 편의 간단한 예제보다 더 실무에 가까운 코드를 본다. Processor가 포함된 구조와, 두 예제의 차이를 비교하면서 "Processor가 왜 필요한가"와 "Writer 선택이 성능에 어떤 영향을 주는가"를 정리할 예정이다.
다음 편 예고
4편에서는 어제 구매 금액 10만원 이상 회원의 등급을 VIP로 변경하는 배치를 만들어본다. 3편의 익명화 배치와 비교하면서 Processor의 역할, JPA Writer의 함정, 실행 방법까지 다룬다.
참고 자료
'Spring Batch' 카테고리의 다른 글
| [Spring Batch] 4편. 실전 코드 패턴과 Reader/Processor/Writer (0) | 2026.04.18 |
|---|---|
| [Spring Batch] 2편. Job, JobInstance, JobExecution의 관계 (1) | 2026.04.18 |
| [Spring Batch] 1편. Spring Batch는 왜 필요할까? (1) | 2026.04.18 |


